

支付对账失败时无需慌张,关键在于合理配置重试机制以平衡效率与稳定性,本文探讨了重试次数设置的艺术与科学:过少可能导致漏单,过多则可能引发系统雪崩,建议采用"指数退避+最大阈值"策略,例如初始间隔5秒,按2倍递增至上限60秒,总重试3-5次,同时需结合业务场景(如高实时性交易缩短间隔)、系统负载(高峰期降低重试频率)及异常类型(网络抖动可重试,账户异常需人工介入)动态调整,通过监控重试成功率、失败原因分布等指标持续优化,配合异步队列、死信机制等容错设计,可构建健壮的对账系统,智能重试不是无限尝试,而是有策略的故障恢复。
当支付对账开始"闹脾气"
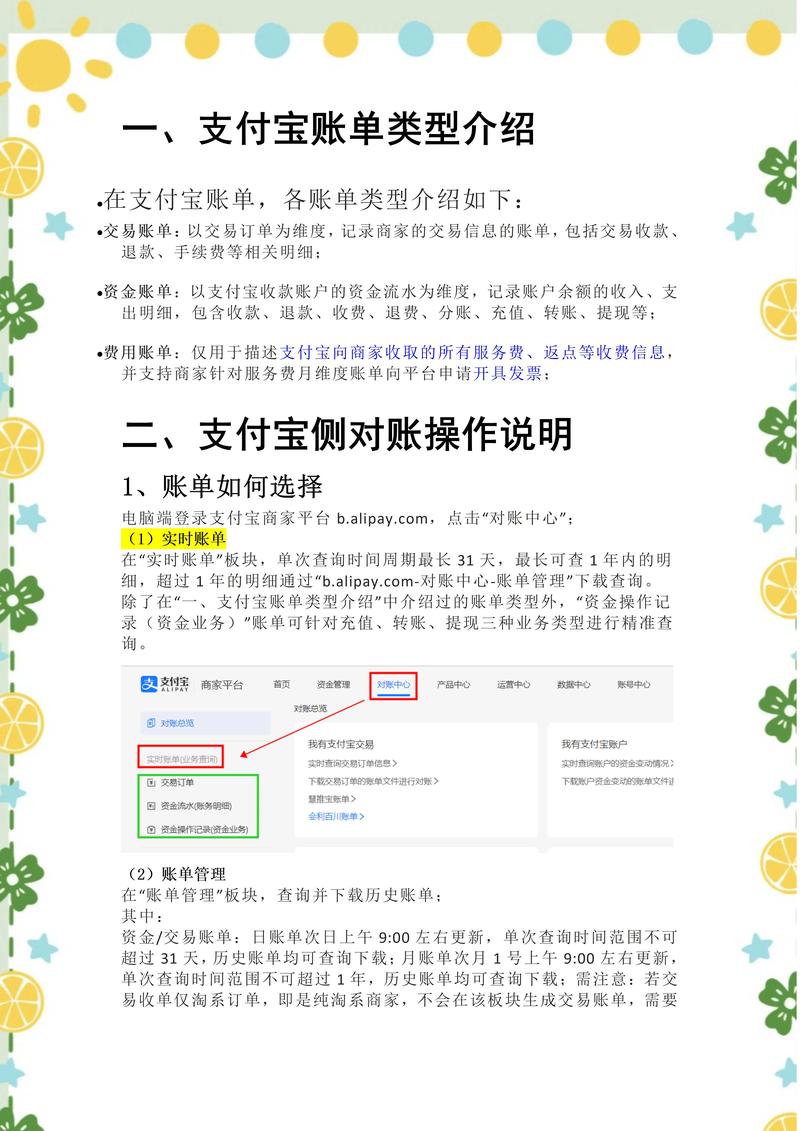
"叮咚!"凌晨3点,手机突然响起警报,睡眼惺忪地打开电脑,发现支付系统对账又失败了,这已经是本周第三次了,财务部的小王明天肯定又要来"讨债",作为技术负责人,我深知支付对账失败不仅影响财务结算,更可能导致资金风险,经过多次实战,我发现合理配置重试次数是解决问题的关键之一。
支付对账失败:那些年我们踩过的坑
1 常见失败原因分析
在我们团队的支付系统运维日志中,过去一年共发生了237次对账失败,通过数据分析,失败原因分布如下:
2 重试机制的价值
面对这些失败,简单的"一锤子买卖"式调用显然不够,合理的重试机制能够:
- 提高对账成功率(我们的数据显示从78%提升至99.5%)
- 减少人工干预(运维人力成本降低60%)
- 保障资金安全(异常交易发现时间从平均4小时缩短至30分钟)
重试次数配置:寻找最佳平衡点
1 黄金法则:3-5-8原则
经过多次实践,我们总结出一个实用的"3-5-8"重试原则:
- 首次失败:等待3分钟后重试(应对短暂网络抖动)
- 二次失败:等待5分钟后重试(应对中等程度问题)
- 三次及以上失败:等待8分钟并发出预警(可能遇到严重问题)
2 基于业务场景的动态调整
不是所有支付业务都适用同样的重试策略:
| 业务类型 | 建议重试次数 | 间隔时间 | 特殊考虑 |
|---|---|---|---|
| 实时支付 | 3次 | 1-2分钟 | 时效性要求高 |
| 批量代发 | 5次 | 5分钟 | 金额大,需谨慎 |
| 跨境支付 | 8次 | 10分钟 | 网络延迟高 |
3 技术实现示例(伪代码)
public class ReconciliationRetryPolicy {
private static final int MAX_RETRIES = 5;
private static final long INITIAL_INTERVAL = 3 * 60 * 1000; // 3分钟
private static final double BACKOFF_MULTIPLIER = 1.5;
public void reconcileWithRetry(PaymentBatch batch) {
int attempt = 0;
while (attempt <= MAX_RETRIES) {
try {
reconciliationService.execute(batch);
return; // 成功则退出
} catch (ReconciliationException e) {
attempt++;
if (attempt > MAX_RETRIES) {
alertService.notifyAdmin(batch, e);
break;
}
long waitTime = (long) (INITIAL_INTERVAL * Math.pow(BACKOFF_MULTIPLIER, attempt - 1));
Thread.sleep(waitTime);
}
}
}
}
进阶技巧:让重试更智能
1 指数退避与抖动算法
简单的固定间隔重试可能导致"惊群效应",我们引入了指数退避加随机抖动的算法:
实际等待时间 = 基础间隔 * (2^尝试次数) ± (随机值)这避免了大量请求同时重试导致的系统过载。
2 熔断机制配合
我们配置了熔断器,当连续失败达到阈值(如5次/分钟),自动暂停对账1小时,防止雪崩效应。
3 基于失败原因的动态调整
通过分析异常类型,智能调整策略:
- 网络超时:立即重试
- 数据不存在:延长等待(可能银行尚未处理完)
- 签名错误:不重试(必须人工干预)
实战案例:从99%到99.99%的跨越
去年双十一,我们的支付系统面临巨大压力,对账失败率一度达到1.2%(平时约0.3%),通过优化重试策略:
- 将峰值时段的重试间隔从5分钟缩短至2分钟
- 针对超时类错误增加快速重试通道
- 实现自动分级警报(邮件→短信→电话)
结果:高峰期对账成功率维持在99.98%,且没有因重试导致系统过载。
监控与优化:重试不是终点
1 关键监控指标
我们建立了完整的监控体系,重点关注:
- 重试成功率曲线
- 平均重试次数分布
- 最终失败原因分类
- 重试耗时占比
2 持续优化闭环
每月分析重试日志,调整策略,例如发现某银行接口在每月25日17:00-19:00响应慢,特别延长该时段的重试间隔。
优雅地处理失败也是一种成功
支付对账就像金融系统的"消化系统",重试机制则是其中的"蠕动调节",没有完美的系统,但通过科学的配置,我们可以让失败变得可控、可预测,好的重试策略不是简单地增加次数,而是要在成功率、时效性和系统负载间找到最佳平衡点。
最后的建议:明天就检查你们的对账重试配置吧!也许一个小小的调整,就能让你告别凌晨3点的警报声。
本文链接:https://www.ncwmj.com/news/5763.html


