

** ,支付结算接口的自动重试机制是保障交易可靠性的关键技术,其核心原理是通过程序化识别接口报错(如网络超时、系统繁忙等),触发预设的重试策略,包括重试次数、间隔时间及终止条件,实践中需权衡成功率与资源消耗,避免因高频重试引发重复支付或系统负载激增,常见方案包括指数退避算法(逐步延长重试间隔)与熔断机制(异常超阈值后暂停请求),需结合幂等性设计(如唯一订单号)确保交易一致性,并通过日志监控与告警系统实时跟踪重试状态,该机制需根据业务场景动态调整参数,兼顾用户体验与系统稳定性。
为什么需要自动重试机制?
在现代支付系统中,接口调用失败是不可避免的,无论是网络抖动、服务器过载,还是第三方服务临时不可用,都可能影响交易的成功率,如果每次失败都直接返回错误,用户体验会大打折扣,甚至导致交易流失。
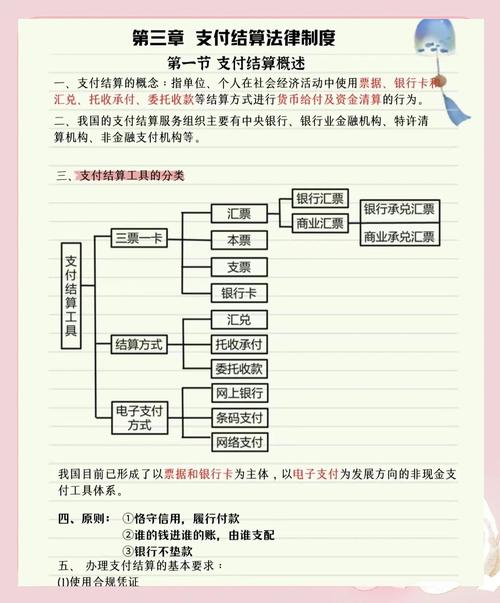
自动重试机制(Auto-Retry Mechanism)就是为了解决这个问题:在接口报错时,系统自动尝试重新发起请求,提高交易成功率,但重试不是无脑进行的,它需要考虑重试策略、幂等性、超时控制等多个因素。
本文将围绕支付结算接口的自动重试机制,从技术原理、常见问题、最佳实践等多个角度展开讨论。
自动重试的基本原理
1 什么情况下需要重试?
不是所有错误都适合重试,以下几种情况可以考虑自动重试:
- 网络问题(如超时、连接中断)
- 服务端临时错误(如HTTP 5xx错误)
- 限流或短暂过载(如HTTP 429 Too Many Requests)
但有些错误(如HTTP 4xx客户端错误)通常不需要重试,因为问题可能在请求本身(如参数错误),重试也无法解决。
2 重试策略:如何科学地重试?
无脑重试可能导致雪崩效应(短时间内大量请求压垮服务),因此需要合理的重试策略:
(1)固定间隔重试(Fixed Delay Retry)
每次重试的间隔时间固定,例如每1秒重试一次。
- 优点:实现简单
- 缺点:可能加剧服务端压力
(2)指数退避(Exponential Backoff)
重试间隔按指数增长(如1s, 2s, 4s, 8s…),避免短时间内密集重试。
- 优点:减少服务端压力,提高成功率
- 缺点:可能增加用户等待时间
(3)随机抖动(Jitter)
在退避基础上加入随机延迟,避免多个客户端同时重试导致“惊群效应”。
支付结算接口的特殊性
支付结算接口不同于普通API,它涉及资金流动,因此必须考虑:
1 幂等性(Idempotency)
支付接口必须是幂等的,即同一笔交易多次提交不会导致重复扣款,常见的实现方式:
- 唯一交易号(Transaction ID):服务端根据ID去重
- Token机制:客户端预申请Token,服务端校验
2 超时与补偿机制
支付接口可能涉及异步回调,如果长时间未收到响应,需要:
- 主动查询:客户端定时查询交易状态
- 人工介入:超时后触发人工对账流程
3 重试次数限制
无限重试可能导致资金风险,通常设置最大重试次数(如3次),超过后触发异常处理流程(如通知运维或人工干预)。
常见问题与解决方案
1 重复支付问题
场景:客户端重试时,服务端可能误认为新请求,导致重复扣款。
解决方案:
- 服务端实现幂等控制
- 客户端记录已提交交易,避免重复提交
2 长尾请求堆积
场景:重试请求堆积,导致后续正常请求被阻塞。
解决方案:
- 采用熔断机制(如Hystrix),错误率过高时暂停重试
- 使用异步队列,避免阻塞主线程
3 跨系统一致性
场景:支付成功但结算失败,如何保证数据一致?
解决方案:
- 分布式事务(如TCC、Saga模式)
- 定时任务补偿:定期检查未结算订单并修复
最佳实践:如何设计健壮的重试机制?
1 客户端 vs 服务端重试
- 客户端重试:适用于临时性错误(如网络抖动)
- 服务端重试:适用于异步处理(如结算回调)
2 监控与告警
- 日志记录:记录每次重试的详细信息
- 告警机制:重试次数超过阈值时触发告警
3 测试与演练
- 模拟故障:通过Chaos Engineering测试重试逻辑
- 压测验证:确保重试不会导致系统崩溃
自动重试是一把双刃剑
自动重试能显著提升支付成功率,但滥用可能导致更严重的问题,合理的设计应包括:
✅ 科学的退避策略(如指数退避+随机抖动)
✅ 严格的幂等控制(避免重复扣款)
✅ 完善的监控机制(及时发现异常)
支付结算无小事,重试机制虽小,却是保障交易稳定性的关键一环,希望本文能帮助你在设计和优化支付系统时,少踩坑、多避雷! 🚀
本文链接:https://www.ncwmj.com/news/6586.html


