

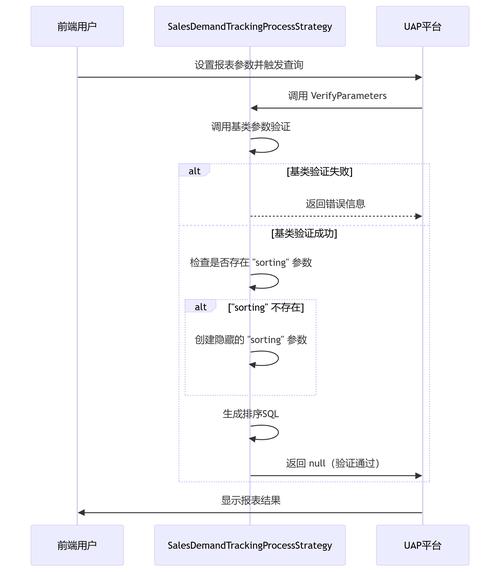
自动发卡网用户列表的排序字段配置需兼顾效率性、安全性与用户体验,其逻辑设计应从多维度综合考量,基础字段如用户ID、注册时间、交易次数等应支持正/倒序切换,满足常规数据筛查需求,敏感字段(如余额、联系方式)需设置权限分级,仅对特定角色开放排序权限以避免信息泄露,技术层面建议采用懒加载与索引优化,确保大数据量下的排序响应速度,同时通过缓存高频排序结果降低服务器压力,用户体验上,可预设"最近活跃""高消费用户"等常用排序模板,并允许管理员自定义排序组合,需注意防注入处理,对所有排序参数进行严格校验,避免SQL注入风险,该设计平衡了功能灵活性与系统稳定性,为运营分析提供高效工具的同时保障数据安全。
排序功能的重要性与复杂性
在自动发卡网系统中,用户列表的排序功能看似简单,实则蕴含着丰富的业务逻辑和技术考量,一个精心设计的排序系统不仅能提升用户体验,还能为运营管理提供有力支持,同时为开发者构建可维护的代码基础,本文将从用户、运营和开发者三个视角,深入探讨自动发卡网用户列表排序字段配置的逻辑设计,揭示这一"小功能"背后的大智慧。
用户视角:便捷性与个性化需求的平衡
用户的核心排序需求
从终端用户的角度来看,排序功能首先应当满足其快速定位目标信息的基本需求,在自动发卡网场景中,用户最关心的排序维度通常包括:
- 时间排序:最新注册/最近活跃用户优先,满足用户追踪最新动态的需求
- 消费金额排序:高消费用户优先,便于识别VIP客户
- 订单数量排序:高频用户优先,识别忠实客户
- 账户状态排序:正常用户优先,过滤异常账户
用户期望这些排序选项能够直观可见、一键切换,而不是隐藏在复杂的菜单中。
个性化排序的隐性需求
随着用户对系统熟悉度的提升,会产生更精细化的排序需求。
- 复合排序:先按消费金额降序,金额相同再按最近购买时间降序
- 自定义权重排序:综合消费金额、订单频率、活跃度等多项指标的加权排序
- 场景化排序:不同业务场景下自动切换预设的排序方案
这些高级需求虽然不为所有用户所需,但对于重度用户或企业客户而言,能显著提升工作效率。
排序交互设计体验
良好的排序交互设计应当遵循"最小惊讶原则":
- 当前排序状态应当清晰可见(如高亮显示的排序字段和方向箭头)
- 排序操作应当即时响应,避免长时间等待
- 排序结果应当有视觉区分(如隔行变色或重要数据突出显示)
- 记住用户最后一次的排序偏好,下次进入时保持一致性
运营视角:数据驱动与业务目标的实现
排序策略与业务指标的关联
从运营管理角度看,排序不仅是功能,更是引导业务关注点的工具,精心设计的排序逻辑可以:
- 突出关键用户:通过将高价值用户排在前面,引导客服优先处理
- 识别异常模式:通过特定排序快速发现批量注册、异常消费等可疑行为
- 评估营销效果:按注册时间排序分析活动期间用户增长曲线
- 优化资源配置:根据用户地域分布排序合理分配服务器节点
动态排序策略的运营价值
静态的排序字段往往难以满足多变的业务需求,因此运营端需要:
- 可配置的排序规则:无需开发介入即可调整排序优先级
- 时段性排序策略:例如促销期间临时调整排序权重
- A/B测试排序效果:对比不同排序方案对转化率的影响
- 异常数据过滤:在排序前自动排除测试账户、黑名单用户等干扰项
排序与权限管理的结合
在多角色运营团队中,排序配置应当与权限体系深度整合:
- 不同角色看到不同的排序字段选项(如客服看不到财务相关排序)
- 敏感字段排序需要二次验证(如按余额排序)
- 重要排序操作记录审计日志(谁在何时修改了排序规则)
开发者视角:可维护性与性能的权衡
排序功能的架构设计
从技术实现角度,排序功能需要考虑以下架构问题:
- 前后端责任划分:前端排序适用于小数据集,后端排序适合大数据量
- 数据库优化:为常用排序字段建立合适索引,避免全表扫描
- 缓存策略:排序结果缓存与数据实时性的平衡
- API设计:排序参数如何优雅地传递到后端(如字段名、方向、分页等)
动态字段排序的技术实现
支持运营可配置的排序规则带来了技术挑战:
// 示例:动态排序的Java实现
public Page<User> getUsers(SortCriteria sortCriteria) {
Specification<User> spec = (root, query, cb) -> {
List<Predicate> predicates = new ArrayList<>();
// 添加基础查询条件...
return cb.and(predicates.toArray(new Predicate[0]));
};
Sort sort = Sort.unsorted();
if (sortCriteria != null) {
sort = Sort.by(sortCriteria.getDirection(), sortCriteria.getProperty());
}
return userRepository.findAll(spec, PageRequest.of(page, size, sort));
}
性能优化策略
大数据量下的排序性能至关重要:
- 延迟加载:先返回少量排序数据,滚动加载更多
- 预计算:为复杂排序指标预先计算并存储结果
- 分片排序:大数据集分片处理后再合并结果
- 异步导出:大量数据排序导出采用后台任务模式
可扩展性设计
良好的排序架构应当支持:
- 新字段的快速接入(通过注解或配置而非硬编码)
- 自定义排序逻辑(如特殊用户的固定置顶)
- 跨表关联排序(如按用户所属分组名称排序)
- 多语言排序支持(不同语言环境的排序规则差异)
综合解决方案:构建智能排序系统
三层排序模型设计
结合三方需求,我们提出以下模型:
- 基础排序层:满足80%常规需求的固定字段快速排序
- 高级排序层:支持多字段组合、条件过滤的复杂排序
- 智能排序层:基于用户行为、机器学习算法的个性化排序
配置化排序规则引擎
通过可视化界面配置排序规则:
// 排序规则配置示例
{
"ruleName": "VIP用户优先",
"priority": 1,
"conditions": [
{
"field": "vipLevel",
"direction": "DESC",
"weight": 0.6
},
{
"field": "lastPurchaseTime",
"direction": "DESC",
"weight": 0.4
}
],
"scope": "ALL",
"validPeriod": {
"start": "2023-01-01",
"end": "2023-12-31"
}
}
智能排序的进阶思考
未来排序系统可以引入:
- 上下文感知排序:根据用户当前操作自动调整排序策略
- 协同过滤算法:"相似用户"喜欢的排序方式也可能适合当前用户
- 实时反馈调整:根据用户的显性反馈(如点击)和隐性反馈(如停留时间)动态优化排序
小功能背后的大格局
自动发卡网用户列表的排序字段配置,远不止是技术实现问题,它体现了产品对用户需求的深刻理解,反映了运营团队的数据驱动思维,也考验着开发者的架构设计能力,一个优秀的排序系统,应当像优秀的服务生一样——既了解常客的固定偏好,又能根据特殊场合灵活调整,始终在不经意间提供恰到好处的服务。
在数字化体验日益重要的今天,这些"看不见的细节"往往成为决定产品成败的关键,排序功能的设计哲学,或许可以概括为:在规律性与灵活性之间,在标准化与个性化之间,在即时响应与长远考量之间,寻找那个完美的动态平衡点。
本文链接:https://www.ncwmj.com/news/6014.html


